A Beginner's Guide to Classification in Machine Learning

Classification is one of the most common machine learning tasks. Put simply, classification involves predicting a category or class for a given input. Spam filtering, image recognition, fraud detection, and medical diagnosis are all examples of classification problems.
In this beginner's guide, we'll cover the fundamentals of classification in machine learning.
Let’s get started!
What is ML Classification?
Classification is the task of predicting a discrete class or category for a given input. It works by developing a model that learns from input data that has been labeled with the correct output.
For example, an image classification model would be trained on images labeled as “dog”, “cat” or other animal classes. Given a new unlabeled image, the model predicts which class the image most likely belongs to.
Classification belongs to the category of supervised machine learning where the model learns patterns from labeled data. The model looks for relationships between input features (like color, shape, size etc.) and a target variable (the class) to make predictions.
Why Use Classification in Machine Learning?
Classification is an incredibly useful technique in machine learning that allows computers to automatically assign categories or classes to data points. There are many reasons why classification is important:
One of the most common uses of classification algorithms is for detecting spam emails. The algorithm is trained on a dataset of emails that have been manually labeled as either "spam" or "not spam" by humans. Based on the words, links, attachments, sender information etc. It learns rules to distinguish between the two categories. After training, when you feed it new emails it can automatically label them as spam or not with decent accuracy.
Benefits of using classification for spam detection:
-
Saves time by automatically separating spam from important emails
-
Improves inbox organization by diverting spam into separate folders
-
Reduces risk of users falling for malicious spam messages
-
Increases productivity by cutting down time spent daily deleting spam
As algorithms improve, classification keeps getting better at mimicking complex human decision making for filtering spam.
Classification has revolutionized medical diagnosis by enabling automated detection of anomalies in scans and tests. Previous approaches relied solely on doctors manually examining X-rays, MRI scans etc. and using intuition to diagnose issues. But human analysis takes time and is prone to error due to fatigue.
Classification modeling in machine learning brings precision, speed and reliability. Models can be trained on labeled datasets of normal and abnormal scans to detect patterns automatically. For e.g. classifiers can analyze MRI images to generate tumor likelihood scores for cancer diagnosis.
Benefits include:
-
Speeds up analysis of large volumes of tests and scans
-
Improves accuracy since algorithms detect hard-to-spot anomalies
-
Enables insights from subtle patterns inaccessible manually
-
Consistency unaffected by human limitations of bias or fatigue
-
Supports doctors by acting as a smart second opinion
As medical imaging and tests generate more digitized data, machine learning classification will continue enhancing and saving lives.
Banks and financial companies lose billions to online fraud every year. But machine learning classification provides a great solution by flagging fraudulent transactions automatically. The classifiers can be trained on vast volumes of past data like customer profiles, transaction
details, locations etc. to learn complex patterns that differentiate genuine and fraudulent behavior.
Benefits of using classification for fraud prevention:
-
Instantly detect fraudulent transactions and stop them
-
Analyze more parameters and at larger scale than humans can
-
Save millions lost annually to false charges, identify theft etc.
-
Improve customer trust and satisfaction
-
Adapt models continually as fraud tactics evolve
As fraudsters come up with ever more sophisticated attacks, classification algorithms will provide the cutting-edge protection needed to thwart them.
Facial recognition is another widely used real-world application of classification. Social networks use it to detect and tag people on uploaded photos automatically by comparing facial features against profile pictures. Law enforcement agencies use it to match faces from surveillance cameras against criminal databases.
Benefits include:
-
Automate organizing huge volumes photos based on people
-
Save time manually tagging friends on social apps
-
Help track down suspects using CCTV footage
-
Enhance security at airports, offices by allowing access based on facial recognition
As cameras and photos become more ubiquitous, facial recognition using classification will help manage and leverage them for legitimate uses.
Sentiment analysis classifies text as expressing positive, negative or neutral opinions. It uses classification algorithms trained on datasets of text labeled manually for sentiment. Based on word choices and language, it learns how to tag sentiment of new text automatically
It enables:
-
Companies to monitor brand and product sentiment across the web and social media
-
Analyze customer conversations at scale to identify pain points
-
Track how PR disasters, political gaffes etc. impact public perception over time
-
Identify rising trends by understanding shifts in consumer preferences
As classification algorithms become more advanced, sentiment analysis will provide richer insights from qualitative data like text, driving competitive advantage. Classification allows automating complex decision-making that would otherwise require extensive human analysis. The patterns learned by models often surpass human-level performance.
Types of ML Classification
There are several types of ML classification tasks depending on the number of classes and how they are organized:
Binary or two-class classification involves predicting one of two possible classes or categories. It is the simplest type of classification task. Binary classification problems have just two class labels to predict between.
Common real-world examples of binary classification include:
-
Spam filtering: Predicting if an email is spam or not spam
-
Fraud detection: Determining if a credit card transaction is fraudulent or valid
-
Medical testing: Testing if a patient has a condition (positive) or not (negative)
-
Online advertising: Classifying users as likely or unlikely to click on an ad
The two classes in binary classification problems are typically represented as 0 and 1. One class generally represents the "normal" state while the other represents the "abnormal" state. For example, emails could be classified as either "spam" (1) or "not spam" (0).
Binary classification forms the basis for other more complex classification tasks. Many multiclass classification algorithms work by combining multiple binary classification models.
- Multiclass Classification
In multiclass classification, there are more than two possible class labels that examples can be categorized into. It is more complex than binary classification.
Some common examples include:
-
Image recognition: Classifying images into fine-grained categories like dog breeds or types of flowers
-
Sentiment analysis: Categorizing product/movie reviews as positive, negative or neutral
-
Diagnosis: Classifying a patient's disease into a category like heart disease, diabetes, cancer etc. based on their symptoms and medical history
The number of possible classes can range from just 3-4 labels up to hundreds or thousands of classes. For example, an image classifier that can recognize hundreds of distinct object categories.
Multiclass classification cannot be modeled as a single binary classification task. Specialized versions of algorithms are needed to handle multiple class labels effectively.
- Multilabel Classification
In multilabel classification, examples are allowed to belong to multiple classes/categories simultaneously unlike singular assignments in multiclass classification.
Some common examples include:
-
Document classification: Assigning multiple topics like sports, politics, tech etc. to news articles and web pages
-
Image annotation: Tagging images with multiple relevant labels like objects present - person, car, tree etc.
-
Diagnosis: Identifying multiple conditions, a patient could have based on symptoms
-
Music genre classification: Categorizing songs into overlapping genres like pop, dance, electronic etc
Multilabel classification enables richer classifications where each example can belong to more than one category. It is a more challenging task algorithmically compared to multiclass classification. Specialized techniques are required for multilabel classification problems.
Real-World Examples of Classification
Here are some common real-world classification use cases across different industries:
-
Healthcare: Diagnosis of diseases from medical images or tests, detecting cancer tumors, analysis of ECG signals.
-
Banking: Fraud prevention in transactions, risk assessment for loans, identify suspicious activities.
-
E-commerce: Product recommendation engines, sentiment analysis of reviews, search optimization.
-
Social media: Spam and inappropriate content moderation, face recognition in photos, object detection.
-
Entertainment: Movie and music recommendations, identifying media content for parental controls.
How Does Classification Work?
The typical workflow for developing a classification model involves:
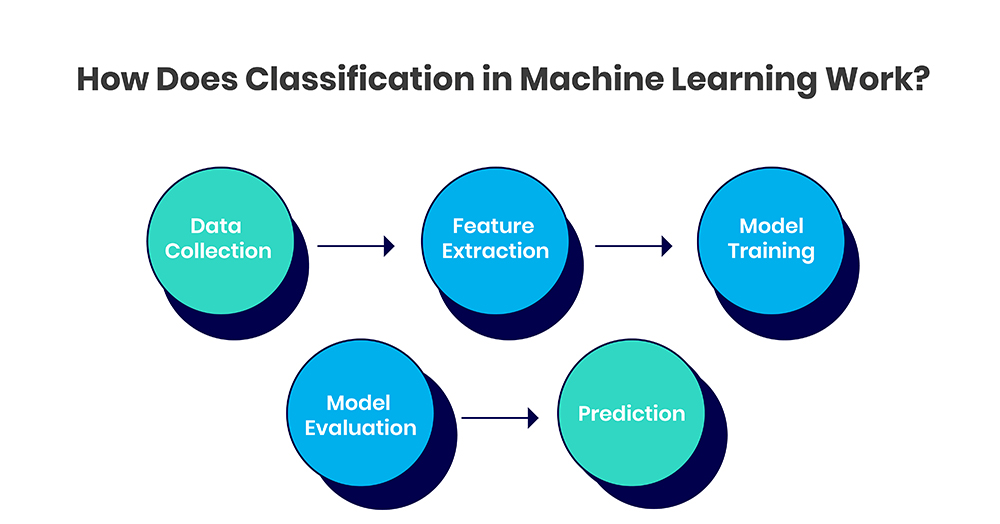
1. Data Collection
The first step in developing a classification model is gathering relevant data and labeling it with the target classes. For example, if building an image classification model to differentiate between cats and dogs, the training data would comprise images of cats labeled as "cat" and images of dogs labeled as "dog". The quality and representativeness of this training data set directly impacts model performance. The data set needs to be sufficiently large and cover the full range of real-world examples.
2. Feature Extraction
Next, the system automatically extracts distinguishing features from the raw input data that help recognize patterns belonging to each class. For image classification, these features could be related to color, texture, shape, or edges. Feature extraction is key to simplifying the data and drawing out the most useful elements for differentiation. The chosen features act as the inputs for the classification algorithm.
3. Model Training
This involves selecting a classification algorithm and training it on the labeled data set. Some common algorithms used are Logistic Regression, Decision Trees, Random Forest, Support Vector Machines etc. Each has its own advantages. The model looks for relationships between the features and labels to learn a mapping function that can predict the label for a new data instance based on its features. The training process continually tweaks model parameters to minimize classification errors.
4. Model Evaluation
Before deployment, the trained model must be thoroughly tested on an unseen data set to evaluate real-world performance. Key metrics like accuracy, precision and recall are used to measure how often the model classifies test data correctly. If performance is found lacking, the model can be retrained after tuning hyperparameters or changing the algorithm itself. The evaluation continues in an iterative manner until the model achieves satisfactory performance.
5. Prediction
In the end, once we have a classification model that is sufficiently accurate, robust and fast, it can be deployed in the real world to predict the label or class of new data points based on patterns learned from training data. As it encounters more real-time data, the model can also incrementally learn and improve over time.
The iterative process of training, evaluation and improvement is crucial to develop a high-quality classification model that continues to deliver accurate and reliable predictions. The workflow requires understanding of datasets, algorithms, parameters and performance metrics to create an optimal system.
Common Classification Algorithms
Classification models use a variety of machine learning algorithms under the hood. Popular options include:
Logistic regression is a simple linear classification method that is easy to implement and provides highly interpretable outputs. It works by estimating the probability of an input belonging to a particular class.
Logistic regression models the probability P(Y=1) where Y is the class variable that can take value 0 or 1. It calculates this probability by applying the logistic function on a linear combination of input variables. The logistic function ensures that the estimated probability lies between 0 and 1.
Some key properties of logistic regression include:
-
Works very well for binary classification problems
-
Easy to train and optimize using gradient-based methods
-
Coefficients can be interpreted to understand impact of variables
-
Performs well when classes are linearly separable
-
Prone to overfitting with irrelevant input features
-
Unable to capture non-linear relationships between independent and dependent variables
Due to its simplicity, interpretability and good generalization capability, logistic regression is applied in many classification tasks such as marketing, healthcare, finance etc.
Support Vector Machines (SVM) analyze input data and recognize patterns for classification and regression analysis. SVMs are especially effective in high dimensional spaces.
An SVM model represents data points as points in space separated into categories by a clear gap. The SVM algorithm finds an optimal boundary between the categories. New data points are then mapped into the space and predicted to belong to a category based on which side of the boundary they fall on.
Key properties and capabilities of SVMs include:
-
Works very well with a clear margin of separation between classes
-
Effective in high dimensional spaces
-
Versatile - can be used for both linear and non-linear classification
-
Memory efficient due to use of support vectors rather than whole dataset
-
Less prone to overfitting compared to other algorithms
-
Kernel functions help capture non-linear relationships
-
Interpretability is challenging for complex SVMs
Because of these strengths, SVMs are extremely popular for classification tasks in text, bioinformatics, computer vision etc. Parameters and kernel selection impact performance significantly.
The K-Nearest Neighbors (KNN) algorithm is a simple classification method that makes predictions based on distance similarity measures to "neighbors" in data space.
It works by finding the K most similar data points in the training set for each data point in the test set. Similarity is measured using distance metrics like Euclidean or Manhattan distance. The test data point is classified based on the most frequent class or average predicted value of its K nearest neighbors.
Key capabilities of KNN algorithm include:
-
Simple and easy to understand with no explicit training phase
-
Versatile algorithm that can be used for both classification and regression
-
Reasonably good performance on most problems
-
No assumptions about underlying data distribution
-
Can capture non-linear relationships
However, KNN does not work well with large datasets or with many irrelevant features. Parameters need careful tuning and computation with datasets having 100K+ samples can be expensive.
Decision trees are predictive models that represent decisions in a tree-like graph structure based on input features. They can be visualized easily and interpreted by humans.
They work by dividing the input space into regions and progressively splitting regions into smaller areas as branches split from the main trunk of the tree. Each leaf node represents a final classification or value.
Some salient properties of decision trees include:
-
High interpretability and easy to visualize + explain
-
Can handle both linear and non-linear relationships
-
Performs embedded feature selection
-
No need to normalize dat
-
Prone to overfitting but can be mitigated by tuning tree depth
Decision trees have become popular across domains like finance, healthcare, and e-commerce for applications like fraud prediction, clinical decision support, targeted marketing etc. Ensembles of shallow trees like Random Forest overcome some limitations.
Random Forest is an ensemble algorithm that combines predictions from multiple decision trees to improve accuracy. The main aim is to reduce overfitting and remove biases.
Random Forest creates multiple decision trees on randomly selected subsets of training data. While splitting nodes, it randomly selects a subset of features to consider. Each tree predicts class/value independently. The forest chooses the most voted class (classification) or mean /average output (regression) across all trees.
Advantages of Random Forest include:
-
Much higher overall accuracy than single decision trees
-
Overfitting mitigated by feature + sample randomization
-
Removes biases and noise sensitivity of individual trees
-
Can capture complex non-linear relationships
-
Integrates seamlessly with missing data
The algorithm does have high memory consumption during the training phase and slower prediction speed due to averaging across trees. But overall, Random Forests have become an essential modeling technique in problems across different domains and data types.
Inspired by biological neural networks, artificial neural networks (ANN) are computing systems that can progressively learn from data patterns and make predictions. They require large datasets for training.
ANNs consist of an input layer that passes information to interconnected hidden layer(s). Final layer generates outputs. Layers contain nodes and interconnections have numeric weights that get adjusted via back propagation as the model learns. The "Learning" actually refers to a model improving its weights.
Capabilities include:
-
Can automatically learn complex relationships between data
-
Ability to detect complex nonlinear relationships
-
Perform robustly in noisy or missing data
-
Can be used for both classification and numeric prediction
-
Prone to overfitting with small datasets
Domain examples include computer vision, forecasting, natural language processing, and pattern recognition applications in finance, healthcare, autonomous vehicles etc. Deep learning models are an advanced class of neural networks that underpin many AI innovations.
Evaluation Metrics for Classification
When building a classification model, it’s important to assess its performance using the right metrics. Simply relying on accuracy may not be enough, especially for imbalanced datasets. Key evaluation metrics like precision, recall, and the F1 score help ensure the model makes reliable predictions. Here’s a quick overview of these essential metrics.
-
Accuracy - Percentage of correct predictions
-
Precision - Of all positives predicted, how many were actually positive
-
Recall - Of all actual positives, how many were correctly predicted
-
F1 score - Harmonic mean of precision and recall
Tracking these metrics ensures your classification models are robust for deployment.
Conclusion
Classification enables automating a variety of real-world decision-making tasks. With the right data and evaluation, classification models can reliably perform common recognition and detection jobs. Understanding these fundamentals empowers you to effectively apply classification across problems. With growing data volumes across industries, its usage will only increase in coming times.




