Adaptive Forgetting in Large Language Models: Enhancing AI Flexibility

Large language models (LLMs) have achieved remarkable success through their ability to learn from vast troves of textual data. Powered by deep neural networks trained on datasets containing trillions of words, LLMs can now generate human-like text, answer complex questions by surfacing relevant information from their memory, and carry out sophisticated language-based tasks. However, one limitation of current LLMs is their static memory - once trained, their memory remains fixed. This inhibits their ability to efficiently adapt to new data or tasks as needs change over time.
In this article, we will explore in more depth how adaptive forgetting could enhance LLMs' learning abilities based on the working of human memory. We'll discuss the current limitations that may help address and examine strategies researchers are developing to implement forgetting in LLMs. The article aims to illustrate why incorporating mechanisms inspired by human cognitive processes, like selective forgetting, represents an important direction for developing more versatile and continually adaptive AI.
The Concept of Adaptive Forgetting
Recent research has pointed to a potential solution - implementing mechanisms of 'adaptive forgetting' in LLMs that allow them to dynamically manage what information stays in memory versus what gets discarded. Taking inspiration from cognitive science research on human memory, forgetting may hold the key to enhancing LLMs' adaptability just as it does the human brain.
Mikel Artetxe, an AI researcher from the University of the Basque Country, led a study exploring this idea. His team proposed periodically 'forgetting' or clearing parts of an LLM memory to make room for new learning, similar to how humans selectively retain some memories while allowing others to fade. Their results demonstrated that introducing forgetting into LLMs' training process led to several beneficial outcomes.
Firstly, it allowed large language models to more efficiently adapt to new languages and datasets with a minimal performance trade-off. By emptying sections of its memory, an LLM can adopt a 'beginner's mind' and learn from a smaller corpus without expectations or biases carried over from its previous training. This is particularly valuable for languages with limited digital resources that LLMs usually struggle to learn adequately from.
Secondly, LLMs with adaptive forgetting maintained higher performance even when training resources like data and computational power were constrained. While typical LLMs experience sharp drops in ability under such conditions, models using adaptive forgetting retained their skills much more robustly. This suggests forgetting enhances LLMs' efficiency and ability to learn from less-than-ideal circumstances.
Lastly, periodic forgetting granted LLMs more flexibility to switch between domains and tasks without complete retraining. By selectively 'rebooting' portions of their memory, LLMs could dynamically reconfigure themselves for new applications. This ongoing adjustability is crucial as the needs of users, businesses and society are constantly evolving.
The study's findings point to a compelling case for incorporating mechanisms of adaptive forgetting into the way LLMs learn and retain information over time. Doing so could help address several limitations in their current abilities to continuously learn throughout their lifetimes, a capability known as 'lifelong learning' or 'continual learning'.
Traditionally, AI systems are designed solely to accumulate more knowledge through training. However human cognition shows that balancing retention with selective forgetting is key for flexible, continuous learning. Our ability to discard details and consolidate memories over time is what frees up brain "space" to assimilate new concepts and experiences.
Forgetting may hold a similar benefit for AI by allowing LLMs to dynamically reallocate their vast memory as needed. This could grant them more human-like learning behaviors - the agility to refocus on new areas, unlearn outdated associations and generalize across multiple domains. It may ultimately lead to AI systems better equipped to evolve alongside constantly changing human knowledge and societies.
The Role of Memory in LLMs
LLMs rely heavily on memory to perform their functions. Their deep neural networks are trained on massive datasets to detect patterns in language and develop associations between words, concepts and contexts. During inference, LLMs can draw from this vast accumulated memory to understand inputs, remember past experiences, and generate coherent, meaningful responses.
Traditional large language model architectures utilize what's known as 'parametric memory' - the trained values of their millions of neural network parameters serve as the model's memory. Information gets encoded into the strengths of connections between neurons. During both training and inference, the model refines these parameters based on new inputs to gradually build up its memory and language proficiency over time.
While parametric memory allows LLMs to leverage massive datasets for superior performance, it also presents limitations. Namely, the memory remains static once training is complete. LLMs lack the ability to dynamically manage what stays in memory versus what gets discarded as needs change. Their memory utilization is fixed rather than adaptive.
As a result, adapting LLMs to new tasks often requires extensive retraining from scratch or "fine-tuning". This demands considerable computational resources as well as the availability of data for the new domain. It also risks the model forgetting capabilities it had previously attained, like a phenomenon known as "catastrophic forgetting". It inhibits LLMs' potential for efficient, lifelong learning over their lifetimes.
The Need for Adaptive Forgetting in LLMs
So how could implementing aspects of forgetting help to address these limitations? Let's consider some of the key challenges that forgetting can potentially alleviate:
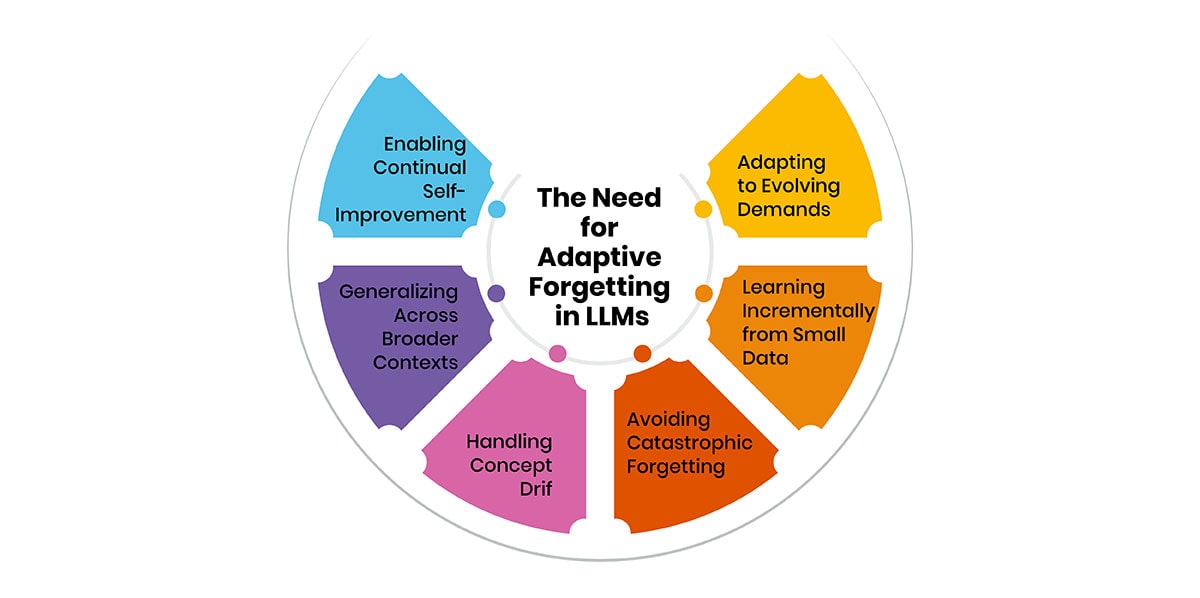
Adapting to Evolving Demands
The tasks, domains and datasets LLMs need to handle are constantly changing as technological and societal needs evolve. Yet their static memory architecture hinders flexibility to dynamically pivot between varied applications. Forgetting could help refresh LLMs' learning by periodically clearing memory slots no longer relevant, readying them to optimally learn specialized new skills.
Learning Incrementally from Small Data
Most state-of-the-art LLMs require vast training datasets containing billions of words. However, collecting such corpora is infeasible for many niche domains or languages. Forgetting could boost LLMs' ability to continually assimilate new concepts from sparse incremental data, like human cognitive capacities.
Avoiding Catastrophic Forgetting
As LLMs expand their skills over time through further training, old abilities risk being overwritten without a trace. Forgetting mechanisms may circumvent this by freeing up memory for new learning while still preserving previously attained proficiencies.
Handling Concept Drift
In open-ended, lifelong learning contexts, the meanings and relationships between concepts can evolve unpredictably over the long run. Forgetting supports reconfiguring memory to adjust to such natural "concept drift", ensuring up-to-date representations.
Generalizing Across Broader Contexts
Human memory’s consolidation process of selective forgetting encourages abstraction and boosts our ability to generalize knowledge across varied situations. The same benefit may apply to LLMs.
Enabling Continual Self-Improvement
For AI to become more autonomously adaptive, it requires the capacity for continual self-guided learning and adjustment throughout its lifetime. Forgetting endows LLMs with greater plasticity to independently refine themselves based on ongoing real-world feedback.
In summary, equipping LLMs with the ability to dynamically manage their vast memory resources, rather than having it fixed post-training, could significantly enhance their potential for lifelong learning behaviors on par with human-level adaptability. Forgetting represents a crucial cognitive mechanism to incorporate.
How Adaptive Forgetting Could Work in LLMs
So how can forgetting to be implemented technologically within LLMs’ existing neural architectures? Researchers are exploring various approaches:
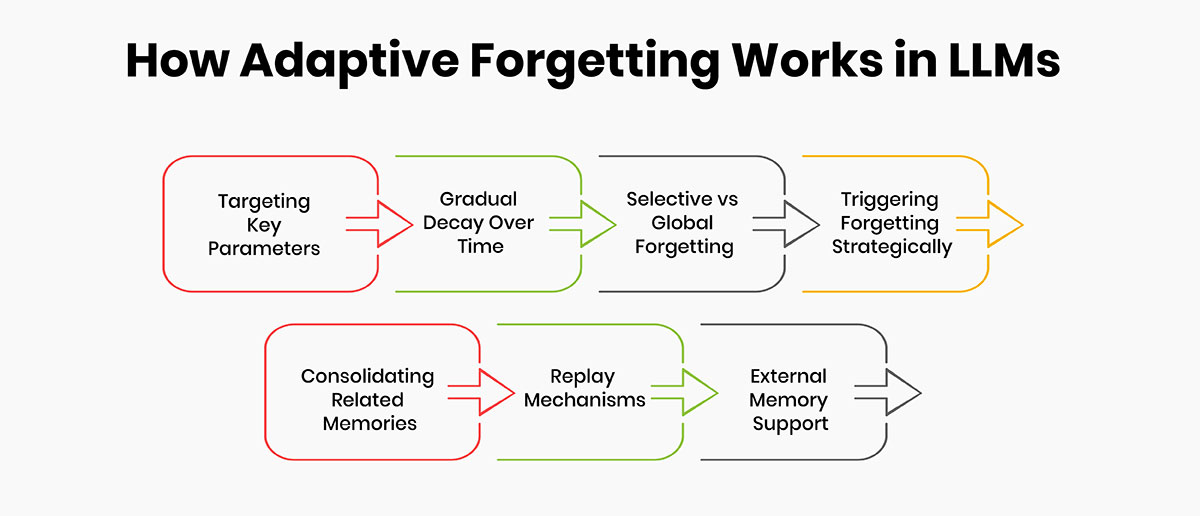
Targeting Key Parameters
The study by Artetxe et al. focused on the embedding layer - the first layer encoding foundational elements of language. By "forgetting" this layer, the connections between words were wiped clean, resetting the model's basic linguistic representations.
Gradual Decay Over Time
Forgetting need not be an abrupt reset but a gradual weakening of infrequently activated connections, simulating natural neural decay. This progressive forgetting could smooth lifelong learning.
Selective vs. Global Forgetting
Forgetting whole layers/networks at once may be too disruptive. Finer-grained schemes targeting only specific parameters, clusters or memory slots could induce more balanced, incremental adaptation.
Triggering Forgetting Strategically
Forgetting might activate after certain training intervals or when performance plateaus to encourage jumps in generalization. External evaluations could also trigger readjustments.
Consolidating Related Memories
Rather than bluntly clearing memory, information could be consolidated by combining related memories into compressed abstract schemas, retaining the gist while forfeiting peripheral details.
Replay Mechanisms
Re-exposing the model to past experiences ("memory replay") may reinforce well-learned associations alongside new learning to prevent catastrophic interference.
External Memory Support
Complementary techniques like memory models, knowledge graphs or model ensembling could help continuously offload and retrieve information to external "episodic" memory stores.
While forgetting remains a nascent area, these strategies represent promising starting points. The goal is inducing neural plasticity through adaptive, intelligent memory management - more dynamic and human-like than static parameters.
Future Directions
Research on adaptive forgetting is still in the early stages but it opens exciting avenues for creating more human-like memory in LLMs. Future developments may involve:
Neuromorphic Approaches
Researchers may look to the human brain for inspiration in developing neuromorphic approaches to memory in AI. Just as the plastic, dynamic nature of human neural circuits enables adaptive forgetting, scientists are exploring ways to implement more biologically plausible memory architectures in LLMs.
Drawing from processes observed in neuroscience could lead to AI systems with memory structures that, like the human brain, are flexible, versatile and continually reorganizing to accommodate new learning while retaining important existing knowledge. This would represent an important step towards mechanical intelligence that, at a fundamental level, functions more like human intelligence.
Adaptive Memory Management
Future work may also involve developing algorithms that allow LLMs to dynamically adjust their allotted memory resources based on the contextual needs of the task at hand. Just as humans prioritize storing information most relevant to our current goals, AI systems with adaptive memory management could allocate more capacity towards domains of greater importance for a given application. This would optimize performance by enabling models to handle diverse challenges competently while making the most efficient use of their computational resources.
Multimodal Memory Architectures
As LLMs expand to integrate multiple data types like text, images and audio, innovative multimodal memory architectures will be required that can meaningfully store, retrieve and learn from varied inputs. Researchers may explore how to build on techniques like adaptive forgetting to develop memory systems capable of associating and synthesizing knowledge across different representational formats, potentially imbuing AI with a more holistic understanding analogous to human cognition.
Balancing Retention and Flexibility
Developing algorithms that skillfully maintain this balance between retaining enough crucial knowledge for functionality while also preserving flexibility for novel learning will remain a priority. The dynamic adjustment of stored memories must be effectively calibrated by context to ensure models can hold onto important learnings from past experiences but stay sufficiently malleable to incorporate new insights and adapt to changes over time.
Integration with Existing Methods
Seamlessly integrating adaptive forgetting techniques within established machine learning pipelines used to train today's powerful LLMs will be important as well. Researchers must determine how best to merge this innovative approach with existing frameworks to both enhance models' abilities and ensure the functionality and safety of real-world AI applications are not disrupted by the transition.
Conclusion
Understanding the role of memory in LLMs is fundamental to advancing generative AI. Adaptive forgetting provides a paradigm shift from static memory models by mimicking human neural plasticity. It holds promise for developing powerful yet inclusive LLMs that can learn continuously without constraints. Future refinements can bring us closer to creating intuitive machines capable of human-level cognition, understanding and collaboration.




